ჯონ მიულერი განმარტავს შეცდომას „Page Indexed Without Content“: როგორ მოვაგვაროთ სერვერული ბლოკირება
ჯონ მიულერი განმარტავს, რომ Search Console-ის შეცდომა „Page Indexed without content“ ჩვეულებრივ სერვერის ან CDN-ის მიერ Googlebot-ის ბლოკირებაზე მიუთითებს და საჭიროებს სასწრაფო რეაგირებას.
Google-ის ძიების ექსპერტმა, ჯონ მიულერმა, განმარტა, რომ Search Console-ში არსებული შეცდომა „Page Indexed without content“ (გვერდი ინდექსირებულია კონტენტის გარეშე), როგორც წესი, სერვერის ან CDN-ის მიერ Googlebot-ის ბლოკირებაზე მიუთითებს და არა JavaScript-თან დაკავშირებულ ხარვეზებზე.
აღნიშნული შეცდომა კრიტიკულია, რადგან პრობლემური გვერდები მალევე იწყებენ Google-ის ინდექსიდან გაქრობას. ხშირ შემთხვევაში, ბლოკირება ხდება IP მისამართების დონეზე, რაც ართულებს პრობლემის იდენტიფიცირებას Search Console-ის ტესტირების ხელსაწყოების მიღმა.
საკითხი Reddit-ზე მას შემდეგ გააქტიურდა, რაც ერთ-ერთმა მომხმარებელმა აღნიშნა, რომ ამ შეცდომის გამოჩენის შემდეგ მისი საწყისი გვერდი ძიების შედეგებში პირველი პოზიციიდან მე-15-მდე ჩამოქვეითდა.
რა იწვევს შეცდომას?
მიულერმა გააქარწყლა გავრცელებული მცდარი მოსაზრება იმის შესახებ, რომ ეს შეცდომა JavaScript-ის დამუშავებას უკავშირდება. მისი თქმით: „როგორც წესი, ეს ნიშნავს, რომ თქვენი სერვერი ან CDN ბლოკავს Google-ს კონტენტის მიღებაში. ეს არ არის დაკავშირებული JavaScript-თან. ეს ძირითადად დაბალი დონის ბლოკირებაა, რომელიც ხშირად Googlebot-ის IP მისამართს ეფუძნება, ამიტომ მისი შემოწმება Search Console-ის ხელსაწყოების გარეშე თითქმის შეუძლებელია“.
Reddit-ის მომხმარებელმა უკვე სცადა დიაგნოსტიკის რამდენიმე მეთოდი: გამოიყენა curl ბრძანებები Googlebot-ის სახელით, შეამოწმა JavaScript-ის ბლოკირება და ჩაატარა Google-ის Rich Results Test. საინტერესოა, რომ დესკტოპის შემოწმების ხელსაწყოებმა აჩვენა შეცდომა „Something went wrong“, მაშინ როცა მობილური ვერსიის ხელსაწყოები ჩვეულ რეჟიმში მუშაობდა.
მიულერმა ხაზგასმით აღნიშნა, რომ სტანდარტული გარე ტესტირების მეთოდები ასეთ ბლოკირებებს ვერ აფიქსირებს. მან ასევე გააფრთხილა საიტის მფლობელები, რომ გვერდები ინდექსიდან მალე გაქრება, ამიტომ საკითხი სასწრაფო რეაგირებას მოითხოვს. აღნიშნული საიტი იყენებს Webflow-ს, როგორც CMS-ს და Cloudflare-ს, როგორც CDN-ს.
რატომ არის ეს პრობლემა მნიშვნელოვანი?
ამ ტიპის პრობლემა არაერთხელ გამხდარა განხილვის საგანი. CDN-ისა და სერვერის კონფიგურაციებმა შესაძლოა შემთხვევით დაბლოკოს Googlebot ისე, რომ ეს ჩვეულებრივ მომხმარებლებზე ან სტანდარტულ ტესტირების ხელსაწყოებზე არ აისახოს. ბლოკირება ხშირად მიმართულია კონკრეტული IP დიაპაზონებისკენ, რის გამოც curl ტესტები და მესამე მხარის სკანერები პრობლემას ვერ პოულობენ.
Google-ის ოფიციალური დოკუმენტაციის თანახმად, სტატუსი „indexed without content“ ნიშნავს, რომ „გარკვეული მიზეზების გამო Google-მა ვერ შეძლო კონტენტის წაკითხვა“. დოკუმენტაციაში ასევე დაკონკრეტებულია, რომ ეს არ არის robots.txt-ით გამოწვეული ბლოკირება. მიზეზი თითქმის ყოველთვის სისტემის უფრო ღრმა შრეებშია.
Cloudflare-ის გამოყენებისას მსგავსი შემთხვევები ადრეც დაფიქსირებულა. წარსულში მიულერი მიუთითებდა „საერთო ინფრასტრუქტურაზე“ (shared infrastructure), როგორც შესაძლო მიზეზზე, როდესაც ბლოკირება ერთდროულად რამდენიმე დომენზე ვრცელდებოდა. მოცემულ შემთხვევაში, ეს შესაძლოა იყოს ბოტებისგან დაცვის წესი (bot protection rule) ან Firewall-ის პარამეტრი, რომელიც Googlebot-ის IP მისამართებს სხვა ტრაფიკისგან განსხვავებულად ეპყრობა.
Search Console-ის URL Inspection ხელსაწყო და Live URL ტესტი რჩება ამ ბლოკირებების იდენტიფიცირების მთავარ საშუალებად. როდესაც ეს ხელსაწყოები აჩვენებს შეცდომას, ხოლო გარე ტესტები წარმატებით გადის, სერვერის დონის ბლოკირება ყველაზე სავარაუდო მიზეზია.
როგორ მოვიქცეთ შეცდომის აღმოსაფხვრელად?
თუ თქვენს საიტზე ხედავთ შეცდომას „Page Indexed without content“, მიჰყევით ამ რეკომენდაციებს:
- შეამოწმეთ CDN და სერვერის კონფიგურაცია: მოძებნეთ წესები, რომლებიც გავლენას ახდენს Googlebot-ის IP დიაპაზონებზე.
- გამოიყენეთ Google-ის IP მისამართების სია: Google აქვეყნებს თავისი სკანერების IP მისამართებს, რაც დაგეხმარებათ იმის დადგენაში, ხომ არ არის ისინი უსაფრთხოების წესების სამიზნე.
- URL Inspection ხელსაწყო: ეს არის ყველაზე საიმედო გზა იმის სანახავად, თუ რას იღებს Google რეალურად გვერდის სკანირებისას. გარე ტესტირების ხელსაწყოები ვერ დააფიქსირებენ IP-ზე დაფუძნებულ ბლოკირებებს.
- Cloudflare-ის მომხმარებლებისთვის: განსაკუთრებული ყურადღება მიაქციეთ ბოტების მართვის პარამეტრებს (bot management settings), Firewall-ის წესებს და IP-ზე დაფუძნებულ წვდომის კონტროლს.
გაითვალისწინეთ, რომ კონფიგურაცია შესაძლოა შეიცვალოს ავტომატური განახლებების ან ახალი ნაგულისხმევი პარამეტრების გამო, მაშინაც კი, თუ თქვენ საიტზე მექანიკური ცვლილებები არ განგიხორციელებიათ.
მსგავსი სტატიები
ინტეგრირებული საძიებო ბრიფი: SEO, PPC და კონტენტის სინქრონიზაცია AI ძიების ეპოქაში
შეიტყვეთ, როგორ შექმნათ ინტეგრირებული საძიებო ბრიფი, რომელიც გააერთიანებს SEO, PPC და კონტენტ გუნდებს AI-ზე დაფუძნებული ძიების ეპოქაში მაქსიმალური შედეგების მისაღწევად.

Google ვალდებულია რეიტინგის მნიშვნელოვანი ცვლილებების შესახებ წინასწარი შეტყობინებები გამოაქვეყნოს
გაერთიანებული სამეფოს CMA-მ Google-ს ახალი მოთხოვნები დაუწესა: კომპანიამ რეიტინგის ობიექტური კრიტერიუმები უნდა გამოიყენოს და მნიშვნელოვანი ცვლილებების შესახებ წინასწარ განაცხადოს.
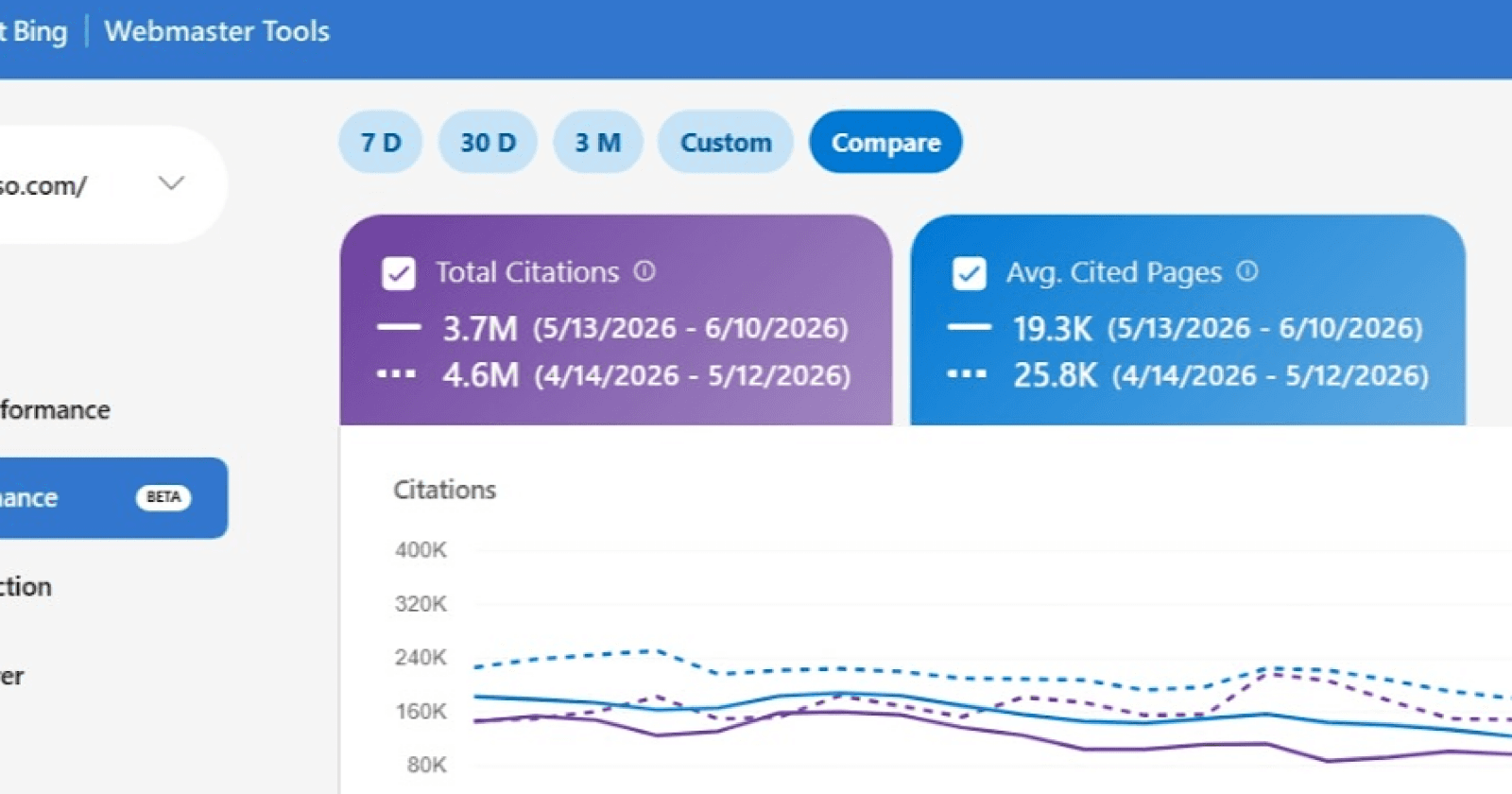
Bing-მა Webmaster Tools-ში ხელოვნური ინტელექტის ციტირების წილის მონიტორინგის ფუნქცია დაამატა
Microsoft-მა Bing Webmaster Tools-ში AI Performance პანელის განახლება დაიწყო, რომელიც საიტის მფლობელებს ხელოვნური ინტელექტის ციტირებებისა და ანალიზის საშუალებას აძლევს.